Step 1: Data preparation and labeling function definition. This step prepares the data and defines the labeling functions. It first imports the Pandas library and defines some constants for the labels. It then creates a DataFrame with movie reviews and splits it into a training set and a test set. The true labels for the test set are defined and converted to a NumPy array. Finally, it defines three labeling functions that label a review as positive, negative, or abstain based on the presence of certain words:
import pandas as pd
# Define the constants
ABSTAIN = -1
POS = 0
NEG = 1
# Create a DataFrame with more data
df = pd.DataFrame({
‘id’: [1, 2, 3, 4, 5, 6, 7, 8],
‘review’: [
“This movie was absolutely wonderful!”,
“The film was terrible and boring.”,
“I have mixed feelings about the movie.”,
“I have no opinion about the movie.”,
“The movie was fantastic and exciting!”,
“I didn’t like the movie, it was too slow.”,
“The movie was okay, not great but not bad either.”,
“The movie was confusing and dull.”
]
})
# Split the DataFrame into a training set and a test set
df_train = df.iloc[:6] # First 6 records for training
df_test = df.iloc[6:] # Remaining records for testing
# Define the true labels for the test set
Y_test = [ABSTAIN, NEG] # Replace this with the actual labels
# Convert Y_test to a NumPy array
Y_test = np.array(Y_test)
Now let’s define the labeling functions, one for positive reviews, one for negative reviews, and one for neutral reviews, using regular expressions as follows:
# Define rule-based labeling functions using regular expressions
@labeling_function()
def lf_positive_review(x):
return POS if ‘wonderful’ in x.review or ‘fantastic’ in x.review else ABSTAIN
@labeling_function()
def lf_negative_review(x):
return NEG if ‘terrible’ in x.review or ‘boring’ in \
x.review or ‘slow’ in x.review or ‘dull’ in \
x.review else ABSTAIN
@labeling_function()
def lf_neutral_review(x):
return ABSTAIN if ‘mixed feelings’ in x.review or \
‘no opinion’ in x.review or ‘okay’ in x.review \
else ABSTAIN
Step 2: Applying labeling functions and majority voting. This chunk of code applies the labeling functions to the training and test sets, and then uses a majority vote model to predict the labels. It first creates a list of the labeling functions and applies them to the training and test sets using PandasLFApplier. It then prints the resulting label matrices and their shapes. It imports the MajorityLabelVoter and LabelModel classes from Snorkel, creates a majority vote mode, and uses it to predict the labels for the training set:
# Apply the labeling functions to the training set and the test set
lfs = [lf_positive_review, lf_negative_review, lf_neutral_review]
applier = PandasLFApplier(lfs=lfs)
L_train = applier.apply(df=df_train)
L_test = applier.apply(df=df_test)
print(L_train)
print(L_test)
print(L_test.shape)
print(Y_test.shape)
Here’s the output:
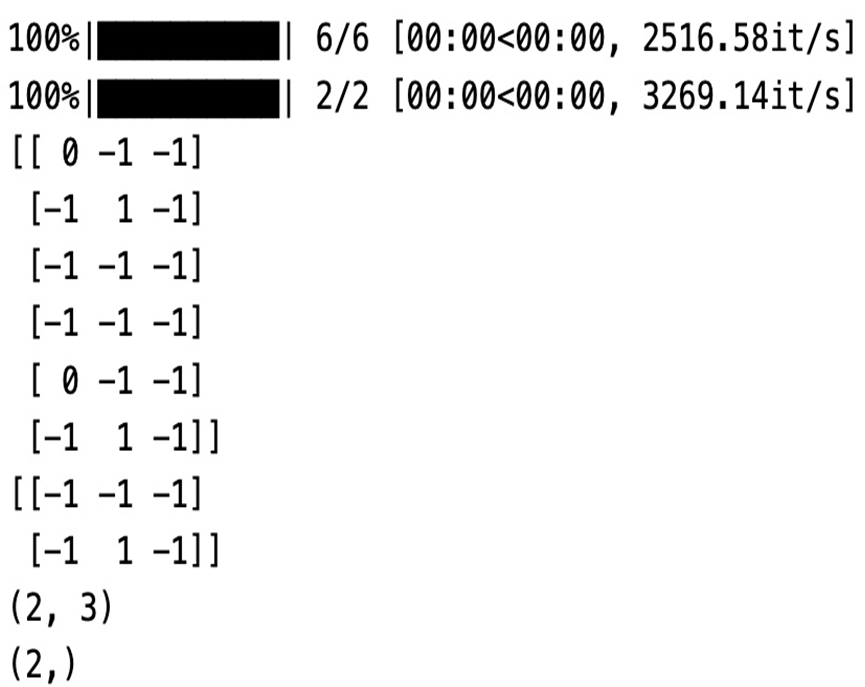
Figure 7.4 – Label matrices
Let’s calculate the accuracy of the model using MajorityLabelVoter model on the test set and print it:
from snorkel.labeling.model import MajorityLabelVoter, LabelModel
majority_model = MajorityLabelVoter()
majority_model.predict(L=L_train)
majority_acc = majority_model.score(L=L_test, Y=Y_test, \
tie_break_policy=”random”)[“accuracy”]
print( majority_acc)
Here’s the output:
1.0
Finally, it predicts the labels for the training set and prints them:
preds_train = majority_model.predict(L=L_train)
print(preds_train)
Here’s the output:
[ 0 1 -1 -1 0 1]
Step 3: Training a label model and predicting labels. This chunk of code trains a label model and uses it to predict the labels. It creates a LabelModel with a cardinality of 2 (for the two labels, positive and negative), fits it to the training set, and calculates its accuracy on the test set:
label_model = LabelModel(cardinality=2, verbose=True)
label_model.fit(L_train=L_train, n_epochs=500, \
log_freq=100, seed=123)
label_model_acc = label_model.score(L=L_test, Y=Y_test, \
tie_break_policy=”random”)[
“accuracy”
]
print(label_model_acc)
Author
Related Posts

Example of video data labeling using k-means clustering with a color histogram – Exploring Video Data
Let us see example code for performing k-means clustering on video data using the open source scikit-learn Python package and the Kinetics...
Read out all
Frame visualization – Exploring Video Data
We create a line plot to visualize the frame intensities over the frame indices. This helps us understand the variations in intensity...
Read out all
Appearance and shape descriptors – Exploring Video Data
Extract features based on object appearance and shape characteristics. Examples include Hu Moments, Zernike Moments, and Haralick texture features. Appearance and shape...
Read out all
Optical flow features – Exploring Video Data
We will extract features based on the optical flow between consecutive frames. Optical flow captures the movement of objects in video. Libraries...
Read out all
Extracting features from video frames – Exploring Video Data
Another useful technique for the EDA of video data is to extract features from each frame and analyze them. Features are measurements...
Read out all
Loading video data using cv2 – Exploring Video Data
Exploratory Data Analysis (EDA) is an important step in any data analysis process. It helps you understand your data, identify patterns and...
Read out all