Text labeling is a crucial task in NLP, enabling the categorization of textual data into predefined classes or sentiments. Logistic Regression, a popular machine learning algorithm, proves effective in text classification scenarios. In the following code, we walk through the process of using Logistic Regression to classify movie reviews into positive or negative sentiments. Here’s a breakdown of the code.
Step 1. Import necessary libraries and modules.
The code begins by importing the necessary libraries and modules. These include NLTK for NLP, scikit-learn for machine learning, and specific modules for sentiment analysis, text preprocessing, and classification:
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import nltk
from nltk.corpus import movie_reviews
from nltk.sentiment import SentimentAnalyzer
from nltk.classify import NaiveBayesClassifier
Step 2. Download the necessary NLTK data. The code downloads the movie reviews dataset and other necessary NLTK data, such as the WordNet lemmatizer and the Punkt tokenizer:
nltk.download(‘movie_reviews’)
nltk.download(‘wordnet’)
nltk.download(‘omw-1.4’)
nltk.download(‘punkt’)
Step 3. Initialize the sentiment analyzer and get movie review IDs. The code initializes a sentiment analyzer and gets the IDs of the movie reviews:
sentiment_analyzer = SentimentAnalyzer()
ids = movie_reviews.fileids()
Step 4. Preprocessing setup. The code sets up the preprocessing tools, including a lemmatizer and a list of English stopwords. It also defines a preprocessing function that tokenizes the text, removes stop words, and lemmatizes the words:
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words(‘english’))
def preprocess(document):
words = word_tokenize(document)
words = [lemmatizer.lemmatize(word) for word in \
words if word not in stop_words]
return ‘ ‘.join(words)
Step 5. Feature extraction. The code sets up a TF-IDF vectorizer with the preprocessing function and uses it to transform the movie reviews into a feature matrix:
vectorizer = TfidfVectorizer(preprocessor=preprocess, ngram_range=(1, 2))
X = vectorizer.fit_transform( \
[movie_reviews.raw(fileid) for fileid in ids])
Step 6. Create a target vector. The code creates a target vector with the categories of the movie reviews:
y = [movie_reviews.categories([f])[0] for f in ids]
Step 7. Split the data. The code splits the data into training and test sets:
X_train, X_test, y_train, y_test = train_test_split( \
X, y, test_size=0.2, random_state=42)
Step 8. Model training. The code initializes a Logistic Regression classifier and trains it on the training data:
model = LogisticRegression()
model.fit(X_train, y_train)
Step 9. Model evaluation. The code evaluates the model on the test data and prints the accuracy:
accuracy = model.score(X_test, y_test)
print(f”Accuracy: {accuracy:.2%}”)
Here’s the output:
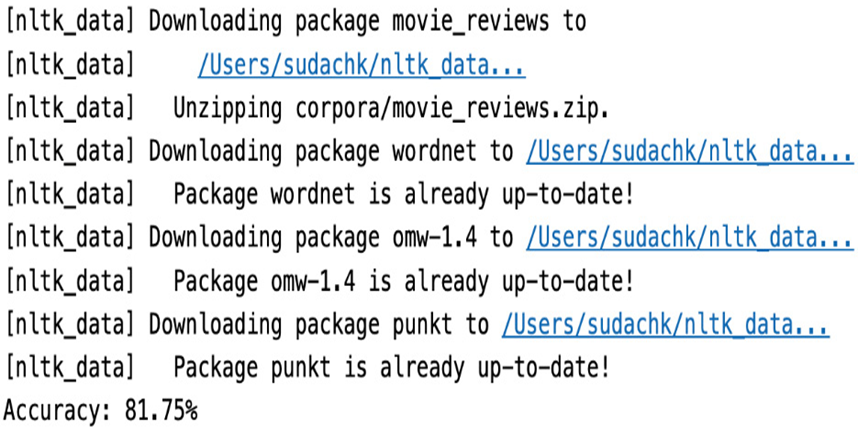
Figure 7.8 – Accuracy of logistic regression
Step 10. Testing with custom sentences. The code tests the model with custom sentences. It preprocesses the sentences, transforms them into features, predicts their sentiment, and prints the results:
custom_sentences = [
“I loved the movie and it was amazing.
Best movie I have seen this year.”,
“The movie was terrible.
The plot was non-existent and the acting was subpar.”,
“I have mixed feelings about the movie.
Some parts were good, but some were not.”,
]
for sentence in custom_sentences:
preprocessed_sentence = preprocess(sentence)
features = vectorizer.transform([preprocessed_sentence])
sentiment = model.predict(features)
print(f”Sentence: {sentence}\nSentiment: {sentiment[0]}\n”)
Here’s the output:

Figure 7.9 – Predicted labels
This code serves as a comprehensive guide to text labeling using logistic regression, encompassing data preprocessing, model training, evaluation, and application to custom sentences.
Now, let’s look into the second method, K-means clustering, to label the text data by grouping similar text together and creating labels for that group or cluster.
Author
marionever@marionever.com
Related Posts

Example of video data labeling using k-means clustering with a color histogram – Exploring Video Data
Let us see example code for performing k-means clustering on video data using the open source scikit-learn Python package and the Kinetics...
Read out all
Frame visualization – Exploring Video Data
We create a line plot to visualize the frame intensities over the frame indices. This helps us understand the variations in intensity...
Read out all
Appearance and shape descriptors – Exploring Video Data
Extract features based on object appearance and shape characteristics. Examples include Hu Moments, Zernike Moments, and Haralick texture features. Appearance and shape...
Read out all
Optical flow features – Exploring Video Data
We will extract features based on the optical flow between consecutive frames. Optical flow captures the movement of objects in video. Libraries...
Read out all
Extracting features from video frames – Exploring Video Data
Another useful technique for the EDA of video data is to extract features from each frame and analyze them. Features are measurements...
Read out all
Loading video data using cv2 – Exploring Video Data
Exploratory Data Analysis (EDA) is an important step in any data analysis process. It helps you understand your data, identify patterns and...
Read out all